Over the course of a few years, we have heard a lot about data and its impact on running a business intelligently. It is not wrong to say that in today’s world data is the most crucial part for any business, conglomerate organization, and small local company.
Everyone needs data to make operations more efficient and make exact predictions about the future. This need for data gave rise to many challenges, one of them being storing and processing of raw datasets.
To store such a huge amount of data, programmers and engineers like you and me came up with many different concepts like data warehouses and data lakes, each having different architectures and applications. As they are the older concept, data warehouses are widely used currently.
Earlier, companies used to set up huge data centers to store and process data, which used to cost a lot to maintain in terms of time, resources, and effort. But with the rise of the internet, cloud service providers like AWS (Amazon Web Services), GCP (Google Cloud Platform), Microsoft Azure, and many more saw opportunities in providing services that help companies with their need of data warehousing. And so, the concept of a cloud data warehouse came into the picture. In this article, I will discuss the services of the two biggest cloud data warehouse providers.
Amazon RedShift
From the introduction, you would have already guessed both services are for cloud data warehousing. But which service is suitable for which application? To choose one of these two services, we need to understand the architecture and operation of these two services. So, let’s start by discovering them one by one.
For starters, AWS Redshift is a fully managed petabyte scalable cloud data warehouse service. In layman’s terms, fully managed means RedShift will take care of setting up and managing the data warehouse and perform tasks like provisioning the right capacity, monitoring clusters, backing up clusters, applying patches, and upgrading to the engine.
RedShift has a three-layer architecture, as shown in the image below:
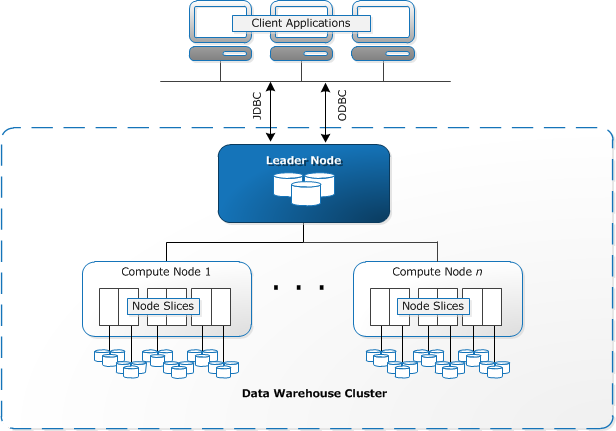
At the lowest level, AWS RedShift is nothing but a cluster made up of a bunch of compute nodes. Depending upon the application, i.e., the size of data and required query performance, number, and type of compute node will vary.
The leader node acts as an intermediary between the client application and the compute nodes. These nodes parse inputs coming from the client application, develop an execution plan and send this aggregated information to compute nodes. These compute nodes execute queries as per the execution plan, transferring data among themselves. Then the aggregated output is sent to the intermediary leader node, which returns the result to the client application.
Some details to keep in mind:
- Each RedShift cluster is run on a RedShift engine.
- Each cluster is built on one or more databases.
- Depending upon the size of data given as input, size of data processed as output, and required operational efficiency, the type of node will vary.
Big Query
So, now we have understood the working of RedShift. Let’s look at the other service: Google’s Big Query.
Google Big Query is a fully managed serverless cloud data warehouse service provided by Google Cloud Platform. Big Query is said to be capable of processing and analyzing terabytes of data with efficiency both in the case of time and operational cost.
To understand how Big Query works, we need to understand its architecture.

By seeing the image attached, you can see that Google Big Query is basically made up of subordinate infrastructure services. The architecture of Google Big Query can be divided into three compartments, which work with each other to the required results. These compartments are compute, storage, and shuffle.
In compute, ‘Dremel’ takes SQL queries from the client application and converts them into an execution tree, slots (leaf nodes), reads the data from the storage, and does the computing. The result is then sent to the mixers, which act like branches of the tree and aggregate all the output data.
Shuffle is nothing but a bridge between compute resources. For this, Google uses the petabyte scalable Jupiter network.
To get more details about Google Big Query, you can check out the documentation on their website.
Which to Choose?
So far, we have a basic understanding of both the services and their architecture. The next question that I will try to answer will be which service you should choose by comparing their different features.
Compute Layer
First and foremost, an important layer of any service is its compute layer. Due to the architecture diagrams above, we know that AWS RedShift virtual machines run ParAccel (which is a partial fork on Postgres). In contrast, Big Query runs on a distributed system on Borg.
Storage Layer
In Big Query, data is stored inside the Colossus filesystem using a columnar format. In AWS, RedShift is stored inside an SSD, HDD, or even an S3 bucket—in some cases, a mixture of all storage types depending on the node selected for RedShift. Both the services use a proprietary storage format.
Data Source
When we talk about data sources, we are talking about which external or internal applications are allowed to set up connections to query the data. Big Query supports more applications for storage as compared to RedShift. RedShift allows you to connect to data imported into S3 or query data through RDS, whereas Big Query allows you to connect to Google Drive, Cloud SQL, and Bigtable.
Encryption of Data
There are two types of encryptions we need to consider. One is when data is at rest, and the other is when data is in transit. Both the services provide methods of encryption during both stages. In AWS RedShift, data is encrypted using AWS managed or customer-managed keys. In Big Query, it is encrypted using Google-managed KMS or customer-managed KMS.
Pricing
Pricing of a service plays an important role as it can make or break the project budget. Pricing of AWS RedShift is a bit tricky to understand as it depends upon the node you selected and the region in which you are working. You can incur additional costs for some special features. But to make things easy, AWS offers a pricing calculator.
Google Big Query follows a simpler on-demand pricing model. You will be billed according to the amount of data streaming through the query, and, like in RedShift, the amount will vary as per the region. Here, it is difficult to predict how much the final bill will be. You can get an approximate value by dry-running your queries.
Scalability
In AWS RedShift, pricing is a bit complicated as pricing not only depends upon the node type but also on the region in which you are using it. Also, using some special features can add additional burden. With the AWS pricing calculator, you get an idea about the cost. Google Big Query uses an on-demand pricing model that makes it a bit difficult as you cannot predict the exact pricing.
Conclusion
There are other points also like access control, data sharing, data access, data loss prevention, backups, and many more. However, it is not possible to cover all these points in one article. I have mentioned a few important ones.
By now, you must have gotten an idea about both the services and their internal working. While selecting a service for your project, you must make a thorough comparison of different aspects of the services. Even the smallest feature can affect a project in a large way.
